
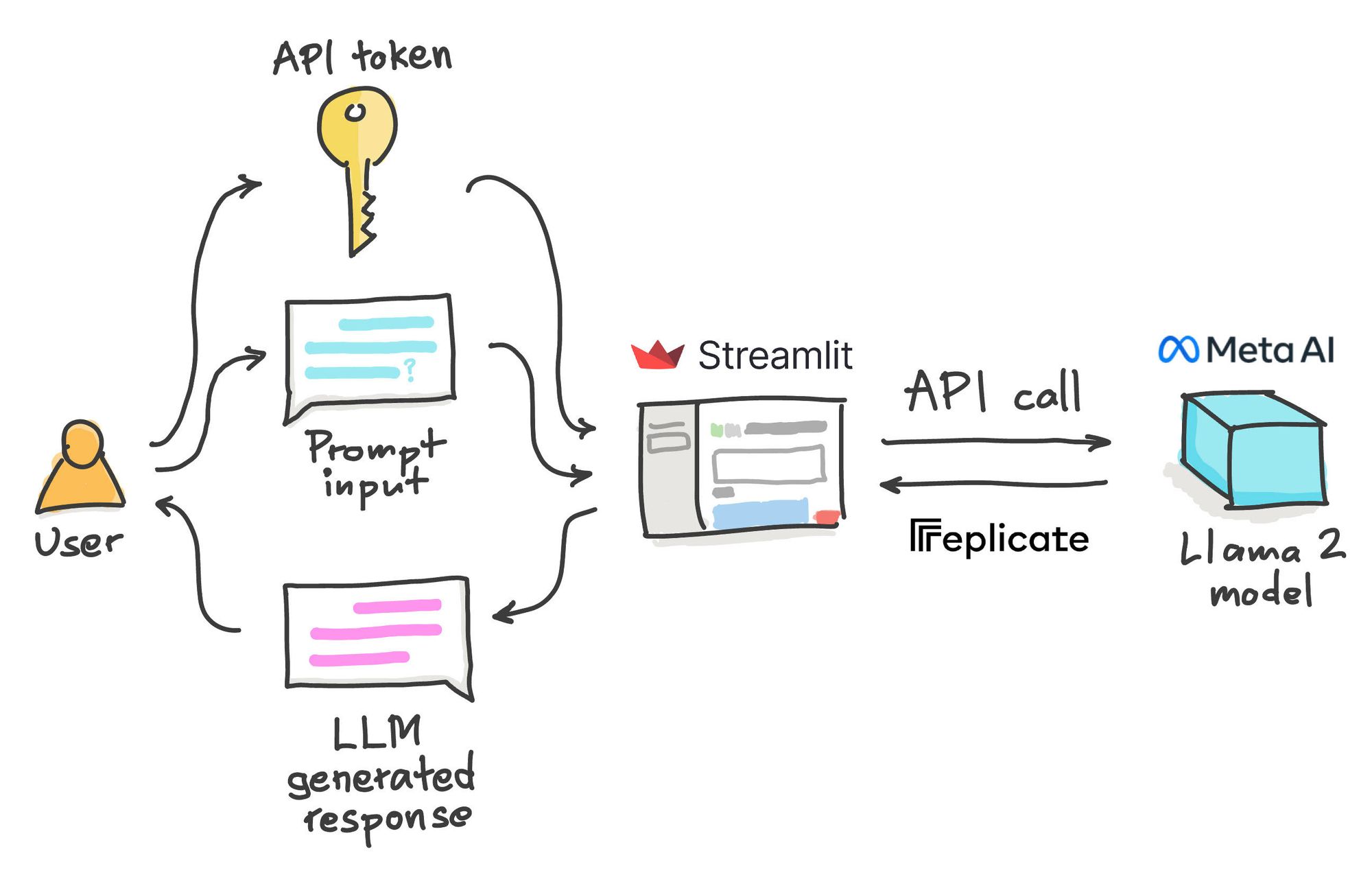
Replicate
Result Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your pets. . . Result Try Llama 2 in our API playground Before you dive in try Llama 2 in our API playground Try tweaking the prompt and see how Llama 2 responds. Result An API to query the model Script to run LLaMA-2 in chatbot mode For the script weve already created a separate tutorial showing step..
Fine-tune Llama 2 with DPO a guide to using the TRL librarys DPO method to fine tune Llama 2 on a specific dataset Instruction-tune Llama 2 a guide to training Llama 2 to. This blog-post introduces the Direct Preference Optimization DPO method which is now available in the TRL library and shows how one can fine tune the recent Llama v2 7B-parameter. The tutorial provided a comprehensive guide on fine-tuning the LLaMA 2 model using techniques like QLoRA PEFT and SFT to overcome memory and compute limitations. In this blog post we will look at how to fine-tune Llama 2 70B using PyTorch FSDP and related best practices We will be leveraging Hugging Face Transformers. This tutorial will use QLoRA a fine-tuning method that combines quantization and LoRA For more information about what those are and how they work see this post..
LLaMA-65B and 70B performs optimally when paired with a GPU that has a. WEB If it didnt provide any speed increase I would still be ok with this I have a 24gb 3090 and 24vram32ram 56 Also wanted to know the Minimum CPU needed CPU tests show 105ts on my. WEB Using llamacpp llama-2-70b-chat converted to fp16 no quantisation works with 4 A100 40GBs all layers offloaded fails with three or fewer Best result so far is just over 8. WEB Llama 2 is broadly available to developers and licensees through a variety of hosting providers and on the Meta website Only the 70B model has MQA for more. WEB Below are the Llama-2 hardware requirements for 4-bit quantization If the 7B Llama-2-13B-German-Assistant-v4-GPTQ model is what youre after..
Pricing for model customization fine-tuning Meta models. In Llama 2 the size of the context in terms of number of tokens has doubled from 2048 to 4096 Your prompt should be easy to understand and provide enough information for the model to generate. Meet Llama 2 Amazon Bedrock is the first public cloud service to offer a fully managed API for Llama 2 Metas next-generation large language model LLM Now organizations of all sizes can. . Special promotional pricing for Llama-2 and CodeLlama models CHat language and code models Model size price 1M tokens Up to 4B 01 41B - 8B 02 81B - 21B 03 211B - 41B 08 41B - 70B..
Streamlit Blog



Comments